Interacción básica de base de datos - Python

Mi proyecto involucra texto de discursos, y explicaré brevemente mi escenario y cómo lo resolví con Python, y espero repasar algunas herramientas que puede integrar en sus propios proyectos. Aquí está el escenario básico:
1 - Relaciones entre colecciones:
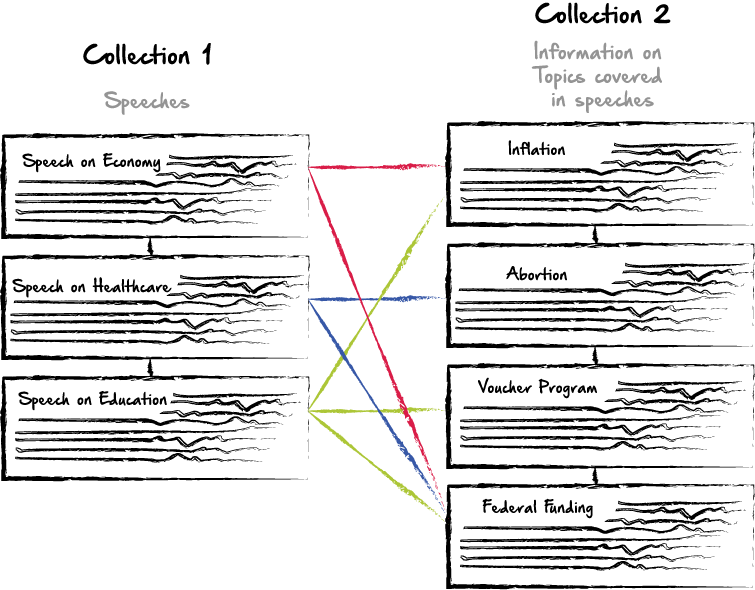
En mi caso, tengo discursos en una colección. Entonces, tengo información en una colección separada. En cada 'discurso', un orador puede hacer referencia a cualquier número de temas sobre los que un usuario podría desear más información. Cada registro en la recopilación de información es básicamente un pequeño párrafo que describe un tema específico, mientras que los discursos son largos y cubren múltiples temas. Entonces, la relación entre las dos colecciones debe ser de uno a muchos, o de muchos a muchos, ya que una charla hará referencia a múltiples temas, y un tema estará asociado con múltiples discursos. Como trabajaré con una base de datos basada en documentos, no usaré tablas, pero usaré python para agregar y crear estas relaciones. Lo primero que pensé hacer era, si encontraba una coincidencia, agregar esa sección de información completa a la primera base de datos. Esa estructura podría verse así:
Solución 1 - Combinando dos colecciones en una colección:

Solución 2: agregar referencias de una colección a otra colección:

Ahora, el proceso de encontrar realmente esas conexiones también podría ser un proceso. Por lo general, en una base de datos SQL, tendría una tabla de unión para estas relaciones de muchas a muchas. Por ejemplo, podríamos tener una tabla de temas. Y si un discurso contiene un tema en esa tabla, y un registro de información también contiene ese tema, vincularíamos la información y el discurso a través de la tabla de temas unidos. Haré un esquema similar con Python, pero en lugar de una tabla, o incluso una segunda base de datos, solo tendré una matriz o una lista de los temas que buscaré, agregaré las conexiones a cada colección y luego puede deshacerse de la lista o guardarla para su uso posterior. Pero de cualquier manera, no necesito agregar esa lista como una colección separada. Así es como podría verse ese proceso en pseudocódigo:
Identificación de colecciones relacionadas con una colección "Join":

Puede ver aquí, mi proceso de pensamiento general sobre esto es tener esta matriz, y lo más probable es que comience recorriendo la colección de discursos. Luego, si algún tema está en la matriz de temas, recorrería la recopilación de información ... si ese tema también se encuentra en alguno de esos registros, tomaría la ID de la recopilación de información y la agregaría en un objeto de referencia dentro de la colección de discursos.
Cosas bastante simples. Hay al menos un par de formas de comenzar con este proceso, y depende en gran medida de dónde se almacenan sus colecciones. Si se almacenan en una base de datos en línea como mlab, entonces tendríamos que importar solicitudes para acceder a la base de datos. Sin embargo, si se almacenan en una base de datos local o en un archivo json, podríamos simplemente acceder a ellos localmente o leerlos desde un archivo json.
Lectura de una base de datos local:
import pymongo
from pymongo import MongoClient
client = MongoClient('mongodb://localhost:27017/')
db = client.politics
speeches = db.speeches
Si ya tenemos la base de datos, pero está almacenada localmente, así es como accederíamos a eso en Python. Necesitaríamos importar pymongo y MongoClient, y luego acceder a nuestra base de datos y luego a la colección que deseamos. Aquí, nuestra colección actual, discursos, ahora se guarda como la variable llamada
speeches , y en este punto podemos recorrerla a nuestro antojo.Lectura de un archivo JSON:
import json
with open('speeches.json') as f:
speeches = json.load(f)
Si
nuestros datos se almacenan como un archivo JSON, simplemente podríamos
importar json, y luego usar el comando con abrir y acceder a nuestros
datos de esa manera. Aquí, nuestros datos ahora se guardan en los speeches variables, y podríamos recorrerlos según sea necesario.Lectura de una base de datos en línea:
import requests
import json
speeches = requests.get("online/database/speeches/url")
Sin embargo, si estamos intentando acceder a la base de datos en línea, importaremos solicitudes y también importaremos json. Aquí, nuestros discursos se guardan en los discursos variables, y podríamos recorrerlos usando algo como,
for i in speeches.json() :En este punto, si hemos importado nuestros discursos, estén donde estén, también tendremos que importar nuestra recopilación de información tópica utilizando un método similar.
Recorriendo los datos:
Probablemente también hay muchas maneras de hacerlo, pero suponiendo que nuestra lista de temas no sea demasiado grande, probablemente podríamos extraer rápidamente las palabras clave y los temas que deseamos buscar tanto en discursos como en colecciones de información temática. Puede ser más fácil hacer esto manualmente. O también hay excelentes API para extraer palabras clave de grandes cantidades de datos, que pueden ser una opción. Ahora, supongamos que la estructura de datos para nuestros discursos y la información tópica es la misma. Algo como esto para los discursos:Estructura de base de datos:
{"_id": "54893893",
"title":"speech on the economy",
"text":"...blab, blah, blah...",
"references": []
}
Y luego una estructura similar para la información tópica:{"_id": "HEJENSHENAH",
"topic":"speech on the economy",
"text":"...blab, blah, blah...",
}
Podríamos configurar nuestro bucle en python, que podría verse así:Python básico para bucle:
for s in speeches:
speechArr = s['text'].split(" ")
for i in speechArr:
if i in topics:
for info in information:
infoArr = info['text'].split(" ")
for x in infoArr:
if x == i:
s['references'].append(info["_id"])
Ahora, probablemente hay formas más simples y más eficientes de hacer esto de lo que se me ocurrió, pero básicamente recorremos el texto del discurso, dividido en una matriz.
Si alguna de las palabras coincide con una palabra en los temas,
recorremos la recopilación de información temática y veremos si el texto
en cualquiera de esos párrafos también coincide con el tema actual.
Si hay una coincidencia, agregamos la identificación de ese registro a
la matriz de referencias en nuestro registro de discursos actual.Si tuviéramos una matriz en nuestro código, podríamos insertar los datos modificados en una nueva matriz, que luego podríamos escribir en una nueva base de datos, guardar como un nuevo archivo JSON o actualizar una base de datos actual.
import json
with open('speeches.json') as f:
speeches = json.load(f)
newSpeeches = []
for s in speeches:
speechArr = s['text'].split(" ")
for i in speechArr:
if i in topics:
for info in information:
infoArr = info['text'].split(" ")
for x in infoArr:
if x == i:
s['references'].append(info["_id"])
newSpeeches.append(s)
Dentro de este ciclo, también podríamos hacer otras cosas para cada registro de la colección. Por ejemplo, si quisiéramos agregar campos en nuestra colección, podríamos hacerlo dentro del ciclo for. Podríamos hacer eso, dentro de nuestro bucle con la siguiente línea de código:i['new_field'] = []si quisiéramos que el nuevo campo fuera una lista. Luego, podríamos agregar datos a la lista dentro de nuestra colección.
En este punto, después de recorrer los datos, podríamos empujar la nueva colección a una base de datos en línea o guardarla en un archivo local, que está contenido en nuestra variable, newSpeeches.
Inserción en una colección local:
En un ejemplo anterior, mencioné cómo podría acceder a una base de datos local. Si ese fuera nuestro método y ahora queremos insertar el nuevo registro en una base de datos local, podríamos hacerlo de esta manera:speechObject_id = speeches.insert_one (speechObject) .inserted_idTendríamos que asegurarnos de que estamos escribiendo las variables apropiadas aquí.
Guardar en un archivo JSON local:
Si abrimos un archivo JSON, o incluso si utilizamos otro método, es posible que queramos guardar la nueva colección en un archivo JSON local. Creo que es una buena idea, ya que tendrá una copia de seguridad si algo le sucede a una base de datos implementada. Así es como lo harías:speeches = []
with open('myspeech.json', 'w') as outfile:
json.dump(speeches, outfile
Si todas nuestras colecciones recién referenciadas se almacenan en la
variable de discursos, entonces lo usaríamos y escribiríamos un nuevo
archivo json con esa información, obviamente necesitando importar json
aquí.Obviamente, hay muchas maneras en que podríamos modificar esto, y probablemente muchas cosas que hice mal, o que podrían mejorar este proceso, por lo que si tiene algún comentario o desea señalar todos mis muchos errores, siéntase libre ! ¡Gracias!
Obtenido de: https://hackernoon.com/basic-database-interaction-python-7e584c04e10f


Comentarios
Publicar un comentario