Construyendo un Web Scraper de principio a fin

¿Qué es un Web Scraper?
Un Web Scraper es un programa que literalmente raspa o recopila datos de sitios web. Tome el siguiente ejemplo hipotético, donde podríamos construir un raspador web que iría a Twitter y recopilar el contenido de los tweets.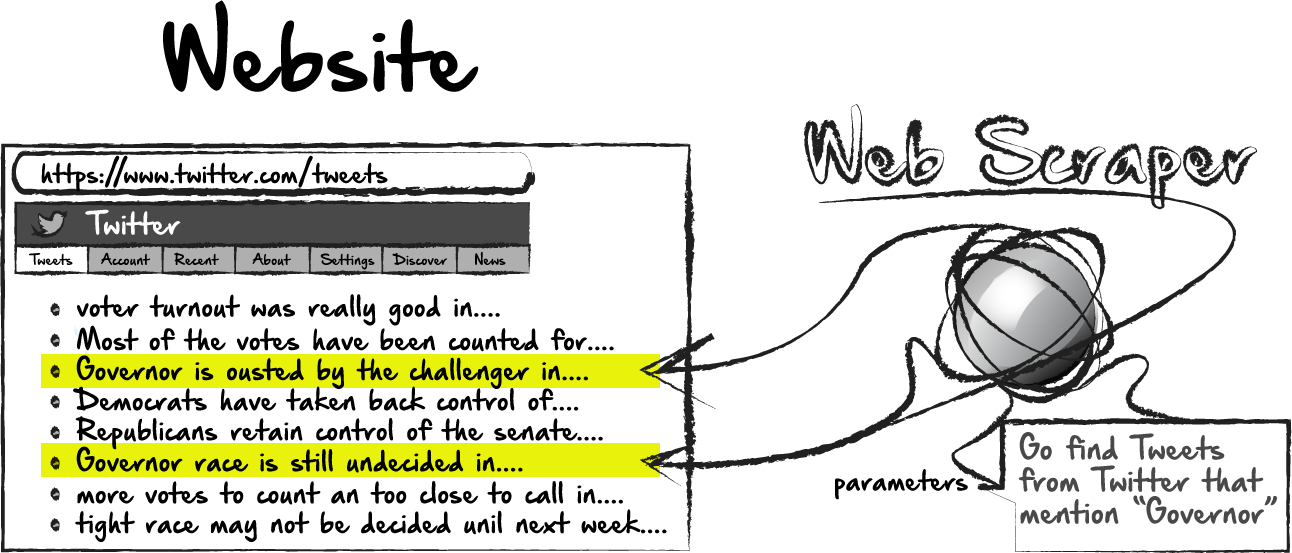
En este punto, podríamos construir un raspador que recopile todos los tweets en una página. Esto puede ser útil. O bien, podríamos filtrar aún más el raspado, pero especificando que solo queremos raspar los tweets si contiene cierto contenido. Aún mirando nuestro primer ejemplo, podríamos estar interesados en recopilar solo tweets que mencionen una determinada palabra o tema, como "Gobernador". Podría ser más fácil recopilar un grupo más grande de tweets y analizarlos más adelante en el back-end. O bien, podríamos filtrar algunos de los resultados aquí de antemano.
¿Por qué son útiles los raspadores web?
¿Qué requisitos previos necesitamos para construir un raspador web?
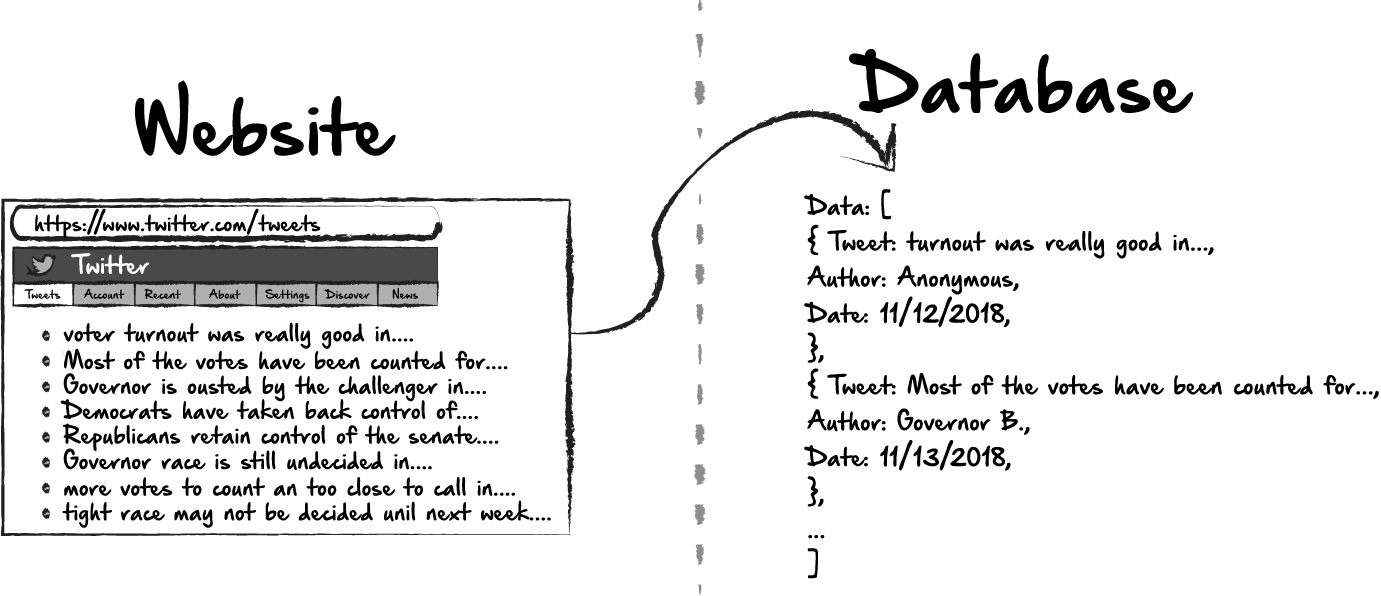
Antes de entrar en detalles sobre cómo funciona un raspador web, demos un paso atrás y hablemos sobre dónde encaja el raspado web en el ecosistema más amplio de tecnologías web. Eche un vistazo al flujo de trabajo simple a continuación:
Para asegurarnos de que todos estamos en la misma página, cubriremos cada uno de estos requisitos previos con cierto detalle, ya que es importante comprender cómo encaja cada tecnología en un proyecto de raspado web. Los requisitos previos de los que hablaremos a continuación son:
- Estructuras HTML
- Conceptos básicos de Python
- Bibliotecas Python
- Almacenar datos como JSON (notación de objetos JavaScript)
1. Estructuras HTML
1.a. Identificación de etiquetas HTML
Si no está familiarizado con la estructura de HTML, un buen lugar para comenzar es abriendo las herramientas para desarrolladores de Chrome. Otros navegadores como Firefox e Internet Explorer también tienen herramientas de desarrollo, pero para este ejemplo, usaré Chrome. Si hace clic en los tres puntos verticales en la esquina superior derecha del navegador, y luego en la opción 'Más herramientas', y luego en 'Herramientas para desarrolladores', verá un panel que aparece como el siguiente: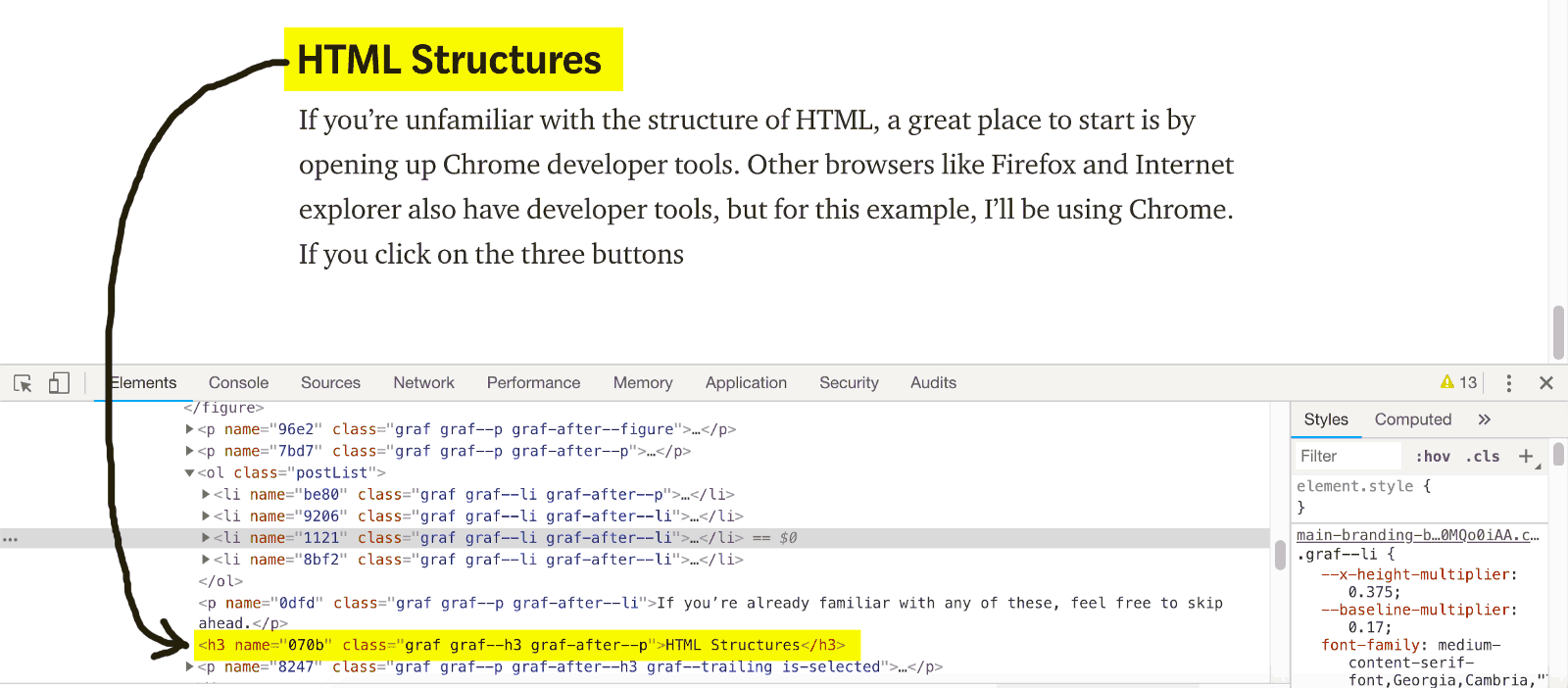
Veamos cómo se vería una estructura HTML típica:
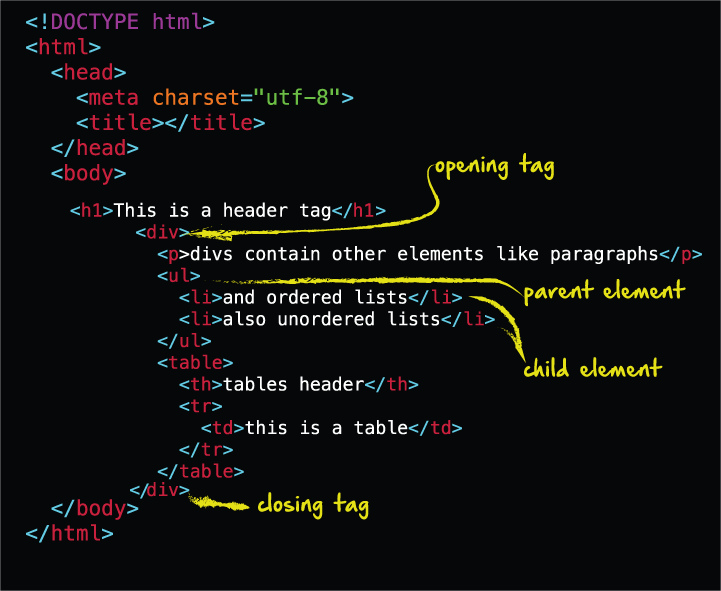
Elementos HTML
Ahora, echemos un vistazo más de cerca a los elementos HTML. Partiendo del ejemplo anterior, aquí está nuestro <h1> o elemento de encabezado:
2. Conceptos básicos de Python
2.a. Configurar un nuevo proyecto
Una ventaja de construir un raspador web en Python es que la sintaxis de Python es simple y fácil de entender. Podríamos estar funcionando en cuestión de minutos con un raspador web Python. Si aún no ha instalado Python, continúe y hágalo ahora:Descargar Python
También tendremos que decidir sobre un editor de texto. Estoy usando ATOM, pero hay muchas otras opciones similares, que hacen relativamente lo mismo. Debido a que los raspadores web son bastante sencillos, nuestra elección en qué editor de texto usar depende totalmente de nosotros. Si desea probar ATOM, no dude en descargarlo aquí:
Descargar Atom
Ahora que tenemos instalado Python y estamos utilizando un editor de texto de nuestra elección, creemos una nueva carpeta de proyecto de Python. Primero, navegue a donde queramos crear este proyecto. Prefiero tirar todo en mi escritorio ya sobrecargado. Luego cree una nueva carpeta y, dentro de la carpeta, cree un archivo. Llamaremos a este archivo "webscraper.py". También queremos crear un segundo archivo llamado "parsedata.py" en la misma carpeta. En este punto, deberíamos tener algo similar a esto:

Si se siente más cómodo configurando este proyecto a través de la línea de comando, no dude en hacerlo.
2.b. Entornos virtuales de Python
Todavía no hemos terminado de configurar el proyecto. En Python, a menudo usaremos bibliotecas como parte de nuestro proyecto. Las bibliotecas son como paquetes que contienen funcionalidades adicionales para nuestro proyecto. En nuestro caso, utilizaremos dos bibliotecas: Beautiful Soup y Requests. La biblioteca Solicitud nos permite realizar solicitudes de URL y acceder a los datos en esas páginas HTML. Beautiful Soup contiene algunas formas fáciles de identificar las etiquetas que discutimos anteriormente, directamente desde nuestro script de Python.Si instalamos estos paquetes globalmente en nuestras máquinas, podríamos enfrentar problemas si continuamos desarrollando otras aplicaciones. Por ejemplo, un programa podría usar la biblioteca de Solicitudes, versión 1, mientras que una aplicación posterior podría usar la biblioteca de Solicitudes, versión 2. Esto podría causar un conflicto, dificultando la ejecución de una o ambas aplicaciones.
Para resolver este problema, es una buena idea configurar un entorno virtual. Estos entornos virtuales son como cápsulas para la aplicación. De esta manera podríamos ejecutar la versión 1 de una biblioteca en una aplicación y la versión 2 en otra, sin conflictos, si creáramos un entorno virtual para cada aplicación.
Primero veamos la ventana de terminal, ya que los siguientes comandos son más fáciles de hacer desde la terminal. En OS X, abriremos la carpeta Aplicaciones, luego abriremos la carpeta Utilidades. Abre la aplicación Terminal. Es posible que también deseemos agregar esto a nuestro dock.
En Windows, también podemos encontrar la línea de terminal / comando abriendo nuestro menú Inicio y buscando. Es simplemente una aplicación ubicada en C: \ Windows \ System32.
Ahora que tenemos el terminal abierto, deberíamos navegar a nuestra carpeta de proyecto y usar el siguiente comando para construir el entorno virtual:
python3 -m venv tutorial-env
Este paso crea el entorno virtual, pero en este momento está inactivo. Para usar el entorno virtual, también necesitaremos activarlo. Podemos hacer esto ejecutando el siguiente comando en nuestra terminal:En Mac:
source tutorial-env/bin/activate
O Windows:tutorial-env\Scripts\activate.bat
3 bibliotecas de Python
3.a. Instalar bibliotecas
Ahora que tenemos nuestro entorno virtual configurado y activado, querremos instalar las bibliotecas que mencionamos anteriormente. Para hacer esto, usaremos el terminal nuevamente, esta vez instalando las Bibliotecas con el instalador pip. Ejecutemos los siguientes comandos:Instalar hermosa sopa:
pip install bs4
Instalar solicitudes:pip install requests
Y ya hemos terminado. Bueno, al menos tenemos nuestro entorno y bibliotecas en funcionamiento.3.b. Importar bibliotecas instaladas
Primero, abramos nuestro archivo webscraper.py. Aquí, configuraremos toda la lógica que realmente solicitará los datos del sitio que queremos raspar.Lo primero que tendremos que hacer es informar a Python que en realidad vamos a usar las Bibliotecas que acabamos de instalar. Podemos hacer esto importándolos a nuestro archivo Python. Puede ser una buena idea estructurar nuestro archivo de modo que toda nuestra importación esté en la parte superior del archivo, y luego toda nuestra lógica viene después. Para importar nuestras dos bibliotecas, solo incluiremos las siguientes líneas en la parte superior de nuestro archivo:
from bs4 import BeautifulSoup
import requests
Si quisiéramos instalar otras bibliotecas en este proyecto, podríamos
hacerlo a través del instalador pip y luego importarlas en la parte
superior de nuestro archivo. Una cosa a tener en cuenta es que algunas bibliotecas son bastante grandes y pueden ocupar mucho espacio. Puede ser difícil implementar un sitio en el que hemos trabajado si está lleno de paquetes grandes.3.c. Libreria Requests de Python
Requests con Python y Beautiful Soup básicamente tendrán tres partes:
La URL es simplemente una cadena que contiene la dirección de la página HTML que pretendemos eliminar.
La RESPUESTA es el resultado de una solicitud GET. Realmente usaremos la variable URL en la solicitud GET aquí. Si miramos cuál es la respuesta, en realidad es un código de estado HTTP. Si la solicitud fue exitosa, obtendremos un código de estado exitoso como 200. Si hubo un problema con la solicitud, o el servidor no responde a la solicitud que hicimos, el código de estado podría no ser exitoso. Si no obtenemos lo que queremos, podemos buscar el código de estado para solucionar el error. Aquí hay un recurso útil para descubrir qué significan los códigos, en caso de que necesitemos solucionarlos: Codigos
Finalmente, el CONTENIDO es el contenido de la respuesta. Si imprimimos todo el contenido de la respuesta, obtendremos todo el contenido en toda la página de la URL que solicitamos.
4. Almacenamiento de datos como JSON
Si no desea pasar el tiempo raspando, y quiere saltar directamente a la manipulación de datos, estos son algunos de los conjuntos de datos que utilicé para este ejercicio:
https://www.dropbox.com/s/v6vjffuakehjpic/stopwords.json?dl=0
https://www.dropbox.com/s/2wqibsa5fro6gpx/tweetsjson.json?dl=0
https://www.dropbox.com/s/1zwynoyjg15l4gv/twitterData.json?dl=0
4.a. Ver datos raspados
Ahora que sabemos más o menos cómo se configurará nuestro raspador, es hora de encontrar un sitio que realmente podamos raspar. Anteriormente, vimos algunos ejemplos de cómo podría ser un raspador de Twitter, y algunos de los casos de uso de dicho raspador. Sin embargo, probablemente no vamos a raspar Twitter aquí por un par de razones. Primero, cada vez que se trata de contenido generado dinámicamente, como sería el caso en Twitter, es un poco más difícil de eliminar, lo que significa que el contenido no es fácilmente visible. Para hacer esto, necesitaríamos usar algo como Selenium, que no abordaremos aquí. En segundo lugar, Twitter proporciona varias API que probablemente serían más útiles en estos casos.
En cambio, aquí hay un sitio de "Twitter falso" que se ha configurado solo para este ejercicio.
http://ethans_fake_twitter_site.surge.sh/
En el sitio anterior "Twitter falso", podemos ver una selección de tweets reales de Jimmy Fallon entre 2013 y 2017. Si seguimos el enlace anterior, deberíamos ver algo como esto:
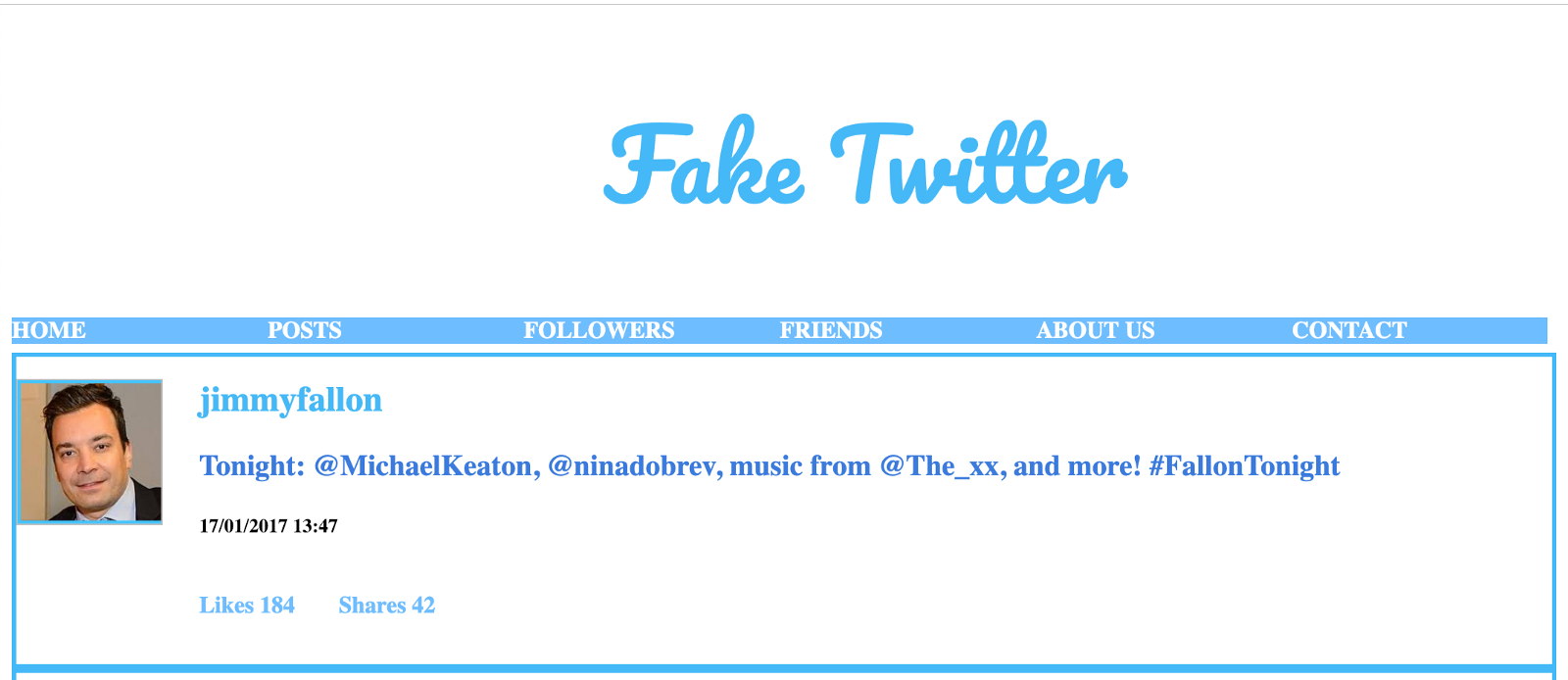
- El Tweet
- El autor (JimmyFallon)
- La fecha y hora
- El número de me gusta
- El número de acciones
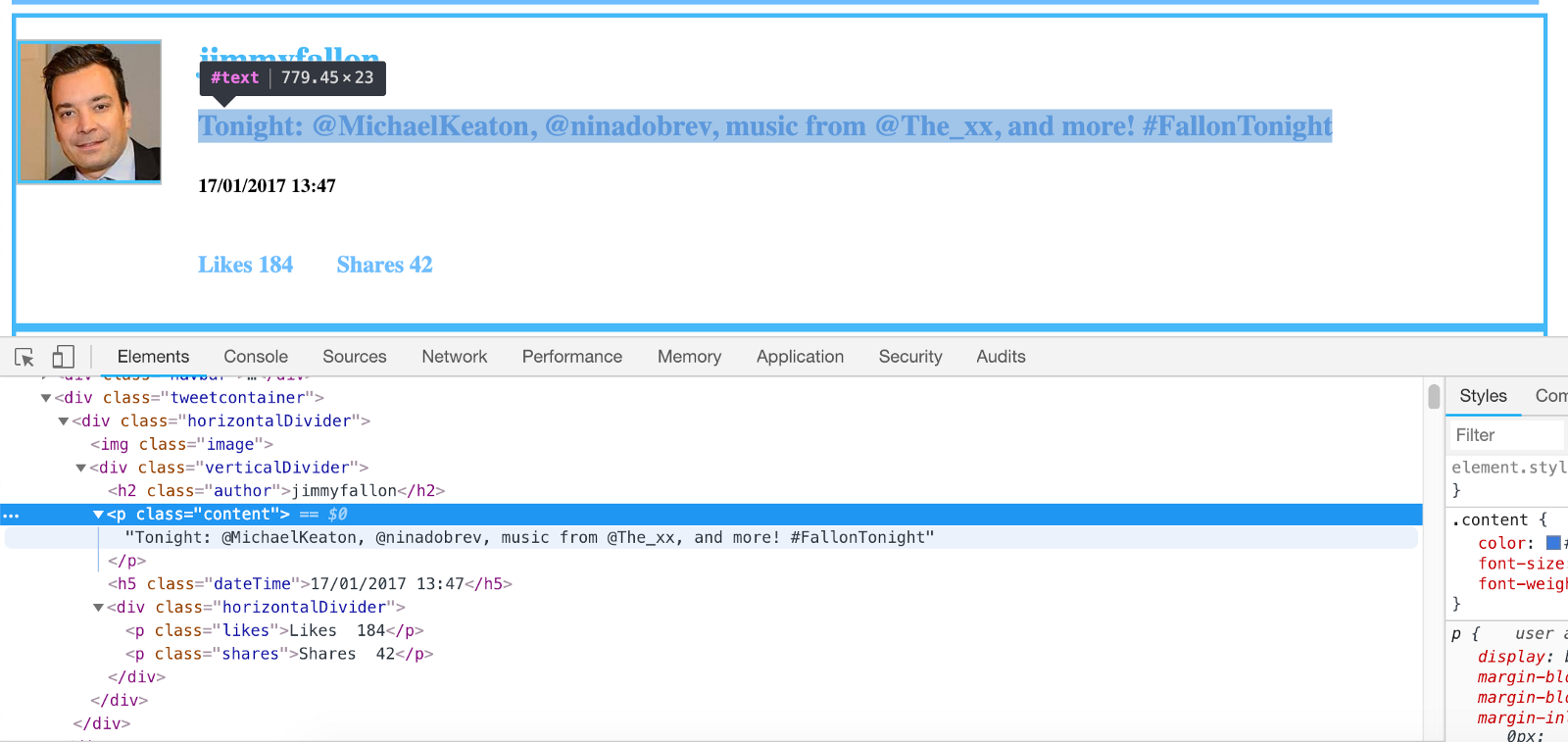
Si usamos el mismo formato que usamos anteriormente para raspar este sitio e imprimir los resultados, probablemente veremos algo similar a esto:
4.b Selectores en Beautiful Soup
Para obtener un tweet, necesitaremos usar los selectores que ofrece beautifulsoup Intentemos esto:
tweet = content.findAll('p', attrs={"class": "content"}).text
print(tweet)
En lugar de imprimir todo el contenido, intentaremos obtener los tweets. Echemos otro vistazo a nuestro html de ejemplo anterior y veamos cómo se relaciona con el fragmento de código anterior:'p', attrs={“class”: “content”} dice, “queremos seleccionar todas las etiquetas de párrafo <p>, pero solo las que tienen la clase llamada“ content ”.Ahora, si nos detuviéramos allí e imprimiéramos los resultados, obtendríamos la etiqueta completa, la ID, la clase y el contenido. El resultado se vería así:
<p class="content> Tonight: @MichaelKeaton, @ninadobrev, music from @The_xx, and more! #FallonTonight</p>
Pero, todo lo que realmente queremos es el contenido o el texto de la etiqueta:Tonight: @MichaelKeaton, @ninadobrev, music from @The_xx, and more! #FallonTonight
Entonces, el .text
le dice a Python que si encontramos una etiqueta <p>, con la
clase "contenido", solo seleccionaremos el contenido de texto de esta
etiqueta.Sin embargo, cuando ejecutamos esta línea de código, solo obtenemos el primer tweet, y no todos los tweets. Parece un poco contra-intuitivo, ya que usamos el método
findAll() . Para obtener todos los tweets, y no solo el primero, tendremos que recorrer el contenido y seleccionarlo en un bucle, así:for tweet in content.findAll('p', attrs={"class": "content"}):
print tweet.text.encode('utf-8')
Ahora, cuando recorramos el contenido, podremos ver todos los tweets. ¡Increíble!4.c Convertir datos raspados a JSON
El siguiente paso en este proceso, antes de almacenar los datos, es convertirlos a JSON. JSON significa JavaScript Object Notation. En Python la terminología es dictados. En cualquier caso, estos datos estarán en forma de pares clave / valor. En nuestro caso, estos datos podrían tener el siguiente aspecto:
tweetObject = {
"author": "JimmyFallon",
"date": "02/28/2018",
"tweet": "Don't miss tonight's show!",
"likes": "250",
"shares": "1000"
}
Cada Tweet tendría este formato y podría almacenarse en una matriz. Esto nos permitiría analizar más fácilmente los datos más adelante.
Podríamos pedirle rápidamente a Python todas las fechas, o todos los me
gusta, o contar la cantidad de veces que se usa "show" en todos los
"tweets". Almacenar los datos de una manera utilizable como esta será la clave para hacer algo divertido con los datos más adelante.
Si nos desplazamos hacia atrás y miramos nuevamente la estructura HTML,
podríamos notar que cada tweet está en un elemento <div> con el
nombre de clase "tweetcontainer". Cada autor, tweet, fecha, etc., estará dentro de uno de estos contenedores. Anteriormente recorrimos todos los datos y seleccionamos los tweets de cada elemento.
¿Por qué no hacemos lo mismo, sino que recorremos cada contenedor para
poder seleccionar la fecha individual, el autor y el tweet de cada uno? Nuestro código podría verse así:for tweet in content.findAll('div', attrs={"class": "tweetcontainer"}):
tweetObject = {
"author": "JimmyFallon",
"date": "02/28/2018",
"tweet": "Don't miss tonight's show!",
"likes": "250",
"shares": "1000"
}
Sin embargo, en lugar de estos datos, queremos seleccionar los datos individuales de cada tweet para construir nuestro objeto. El resultado final sería:from bs4 import BeautifulSoup
import requests
url = 'http://ethans_fake_twitter_site.surge.sh/'
response = requests.get(url, timeout=5)
content = BeautifulSoup(response.content, "html.parser")
tweetArr = []
for tweet in content.findAll('div', attrs={"class": "tweetcontainer"}):
tweetObject = {
"author": tweet.find('h2', attrs={"class": "author"}).text.encode('utf-8'),
"date": tweet.find('h5', attrs={"class": "dateTime"}).text.encode('utf-8'),
"tweet": tweet.find('p', attrs={"class": "content"}).text.encode('utf-8'),
"likes": tweet.find('p', attrs={"class": "likes"}).text.encode('utf-8'),
"shares": tweet.find('p', attrs={"class": "shares"}).text.encode('utf-8')
}
print(tweetObject)
¡Increíble! Todos nuestros datos están en un formato agradable y fácil de usar. Aunque, hasta este punto, todo lo que hemos hecho es imprimir los resultados. Agreguemos un paso final y guardemos los datos como un archivo JSON.
4.d Guardar los datos
Para hacer esto, agregaremos una importación más a nuestro código en la parte superior e importaremos json. Esta es una biblioteca central, por lo que no necesitamos instalarla a través de pip como lo hicimos con los otros paquetes. Luego, después de recorrer nuestros datos y construir el tweetobject de cada elemento, agregaremos ese objeto, o dict a nuestro tweetArr, que será una matriz de tweets. Finalmente, aprovecharemos la biblioteca json y escribiremos un archivo json, utilizando nuestra matriz de tweets como datos para escribir. El código final podría verse así:
import requests
import json
url = 'http://ethans_fake_twitter_site.surge.sh/'
response = requests.get(url, timeout=5)
content = BeautifulSoup(response.content, "html.parser")
tweetArr = []
for tweet in content.findAll('div', attrs={"class": "tweetcontainer"}):
tweetObject = {
"author": tweet.find('h2', attrs={"class": "author"}).text.encode('utf-8'),
"date": tweet.find('h5', attrs={"class": "dateTime"}).text.encode('utf-8'),
"tweet": tweet.find('p', attrs={"class": "content"}).text.encode('utf-8'),
"likes": tweet.find('p', attrs={"class": "likes"}).text.encode('utf-8'),
"shares": tweet.find('p', attrs={"class": "shares"}).text.encode('utf-8')
}
tweetArr.append(tweetObject)
with open('twitterData.json', 'w') as outfile:
json.dump(tweetArr, outfile)
Al ejecutar esto, Python debería haber generado y escrito un nuevo archivo llamado twitterData. ¡Ahora intentemos analizar esos datos!5. Análisis/Parsing de datos JSON
Volvamos a nuestro árbol de archivos y abramos nuestro archivo de análisis (parsedata.py), que debe estar en blanco.import json
with open('twitterData.json') as json_data:
jsonData = json.load(json_data)
Ahora, podemos usar la variable jsonData. Esto debería contener toda la información que eliminamos, pero en formato JSON. Comencemos con algo simple, imprimiendo todas las fechas de todos los tweets:for i in jsonData:
print(i['date'])
Al ejecutar este comando, deberíamos ver una lista generada de todas las fechas de todos los tweets.Otra cosa divertida sería ver con qué frecuencia aparecen ciertas palabras en los tweets. Por ejemplo, podríamos ejecutar una consulta que vería con qué frecuencia aparece "Obama" en los tweets:
for i in jsonData:
if "obama" in i['tweet'].lower():
print(i)
Hacer esto nos mostrará el objeto de tweet completo para cada tweet donde se menciona "obama". Muy bien, ¿verdad? Obviamente, las posibilidades son infinitas.
Debe quedar claro ahora, lo fácil que es raspar eficientemente los
datos de la web y luego convertirlos a un formato utilizable para
analizarlos. ¡Fantástico!Fuente: https://hackernoon.com/building-a-web-scraper-from-start-to-finish-bb6b95388184


Comentarios
Publicar un comentario