Web Scraping con Python y BeautifulSoup - TheMenYouWantToBe&Co
Al realizar tareas de ciencia de datos, es común querer usar datos encontrados en Internet. Por lo general, podrá acceder a estos datos en formato CSV o mediante una Interfaz de programación de aplicaciones (API). Sin embargo, hay ocasiones en que solo se puede acceder a los datos que desea como parte de una página web. En casos como este, querrá usar una técnica llamada raspado web para obtener los datos de la página web en un formato en el que pueda trabajar dentro de su análisis.
Hoy, le mostraré cómo realizar el raspado web con Python3 y la biblioteca BeautifulSoup.
Antes de seguir adelante, me gustaría compartir algunos de los componentes básicos de una página web
Cada vez que visita un sitio web o una página web, su navegador web realiza una solicitud a un servidor web. Esta solicitud se llama una solicitud
GET , ya que estamos recibiendo archivos del servidor. El servidor luego envía archivos que le indican a nuestro navegador cómo representar la página para nosotros. Los archivos se dividen en algunos tipos principales: - HTML - contiene el contenido principal de la página.
- CSS : agrega estilo para que la página se vea mejor.
- JS - Los archivos Javascript agregan interactividad a las páginas web.
- Imágenes: los formatos de imagen, como JPG y PNG permiten que las páginas web muestren imágenes.
Después de que nuestro navegador recibe todos los archivos, muestra la página y nos la muestra.
Hay muchas cosas detrás de escena que hacen que una página se muestre
bien, pero no tenemos que preocuparnos por la mayor parte del tiempo
cuando estamos haciendo web scraping. Cuando realizamos el rastreo web, nos interesa el contenido principal de la página web, por lo que nos fijamos en el HTML.
HTML
HTML es el lenguaje de marcado estándar para crear páginas web.
- HTML significa Hyper Text Markup Language
- HTML describe la estructura de las páginas web utilizando el marcado
- Los elementos HTML son los componentes básicos de las páginas HTML.
- Los elementos HTML están representados por etiquetas
- Las etiquetas HTML etiquetan partes de contenido como "encabezado", "párrafo", "tabla", etc.
- Los navegadores no muestran las etiquetas HTML, pero las utilizan para representar el contenido de la página
Un documento HTML simple
Ejemplo
<! DOCTYPE html>
<html>
<head>
<title> Título de la página </title>
</head>
<body> <h1> Mi primer encabezado </h1>
<p> Mi primer párrafo. </p>
<html>
<head>
<title> Título de la página </title>
</head>
<body> <h1> Mi primer encabezado </h1>
<p> Mi primer párrafo. </p>
</body>
</html>
</html>
Inténtalo tú mismo
Ejemplo explicado
- La declaración
<!DOCTYPE html>define este documento como HTML5 - El elemento
<html>es el elemento raíz de una página HTML - El elemento
<head>contiene metainformación sobre el documento. - El elemento
<title>especifica un título para el documento - El elemento
<body>contiene el contenido de la página visible. - El elemento
<h1>define un encabezado grande - El elemento
<p>define un párrafo
Más detalles se refieren a estos tutoriales HTML
¿Qué es web scraping?
El raspado web , el aprovechamiento web o la extracción de datos web son raspados de datos utilizados para extraer datos de sitios web . [1] El software de rastreo web puede acceder a la World Wide Web directamente mediante el Protocolo de transferencia de hipertexto , o mediante un navegador web.
Si bien un usuario de software puede realizar manualmente el raspado
web, el término generalmente se refiere a procesos automatizados
implementados utilizando un bot o rastreador web . Es una forma de copia, en la que se recopilan y copian datos específicos de la web, generalmente en una base de datos local central u hoja de cálculo, para su posterior recuperación o análisis .
Más detalles se refieren a Wikipedia.
¿Por qué necesitamos Web Scraping?
Una gran organización deberá mantenerse actualizada con los cambios de información que se producen en multitud de sitios web. Un raspador web inteligente encontrará nuevos sitios web de los que necesita eliminar los datos.
Los enfoques inteligentes identifican los datos modificados, los
extraen sin extraer los enlaces innecesarios presentes y navegan entre
los sitios web para monitorear y extraer información en tiempo real de
manera eficiente y efectiva.
Puede monitorear fácilmente varios sitios web simultáneamente mientras
se mantiene actualizado con la frecuencia de las actualizaciones.
Observará, como se mencionó anteriormente, que los datos en los sitios web cambian constantemente. ¿Cómo sabremos si una organización ha realizado un cambio clave? Digamos que ha habido un cambio de personal en la organización, ¿cómo se enterará de eso? Ahí es donde viene la función de alertas en el raspado web.
Las técnicas de raspado web inteligente lo alertarán sobre los cambios
de datos que se han producido en un sitio web en particular, lo que lo
ayudará a controlar oportunidades y problemas.
Web Scraping usando Python y BeautifulSoup
En primer lugar, te mostraré con una página web HTML muy básica. Y más adelante, le mostrará cómo hacer raspado web en las páginas web del mundo real.
Lo primero que tendremos que hacer para raspar una página web es descargar la página. Podemos descargar páginas usando la biblioteca de peticiones de Python. La biblioteca de solicitudes realizará una solicitud
GET a un servidor web, que descargará los contenidos HTML de una página web determinada para nosotros. Hay varios tipos diferentes de solicitudes que podemos hacer usando requests , de las cuales GET es solo una.
Intentemos descargar un sitio web de muestra simple,
http://dataquestio.github.io/web-scraping-pages/simple.html . Primero deberemos descargarlo utilizando el método requests.get . 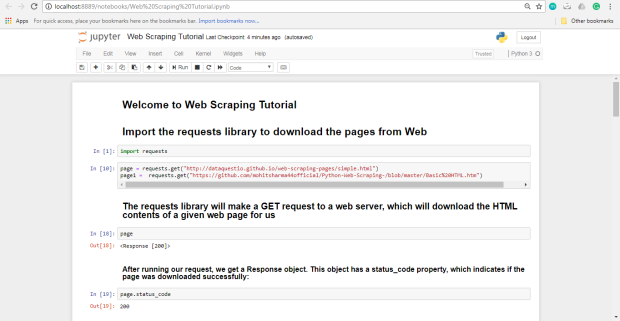
Después de ejecutar nuestra solicitud, obtenemos un objeto de respuesta . Este objeto tiene una propiedad de
status_code , que indica si la página se descargó correctamente.
Podemos imprimir el contenido HTML de la página usando la propiedad de
content : 
BeautifulSoup
Podemos usar la biblioteca BeautifulSoup para analizar este documento y extraer el texto de la etiqueta
p . Primero tenemos que importar la biblioteca y crear una instancia de la clase BeautifulSoup para analizar nuestro documento:
Ahora podemos imprimir el contenido HTML de la página, bien formateado, usando el método
prettify en el objeto BeautifulSoup : 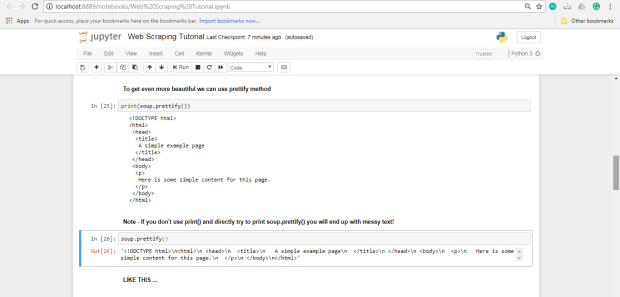
Como todas las etiquetas están anidadas, podemos avanzar a través de la estructura de un nivel a la vez. Primero, podemos seleccionar todos los elementos en el nivel superior de la página usando la propiedad
children de soup . Tenga en cuenta que los children devuelven un generador de lista, por lo que necesitamos llamar a la función de list en él. 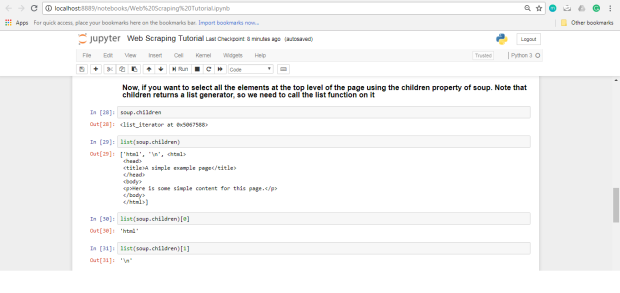
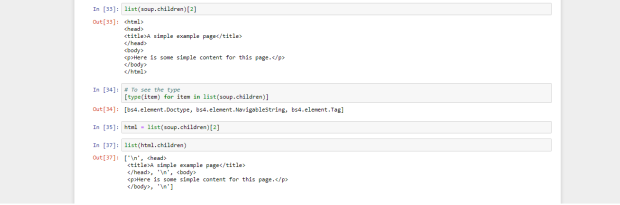
Como puedes ver arriba, hay dos etiquetas aquí,
head y body . Queremos extraer el texto dentro de la etiqueta p , así que nos sumergiremos en el cuerpo (consulte justo arriba, debajo de html.children).
Ahora, podemos obtener la etiqueta
p encontrando a los hijos de la etiqueta corporal 
Podemos usar el método
get_text para extraer todo el texto dentro de la etiqueta. Encontrar todas las instancias de una etiqueta a la vez.
Lo que hicimos anteriormente fue útil para descubrir cómo navegar por
una página, pero se necesitaron muchos comandos para hacer algo bastante
simple. Si queremos extraer una sola etiqueta, podemos usar el método
find_all , que encontrará todas las instancias de una etiqueta en una página.
Si, en cambio, solo desea encontrar la primera instancia de una etiqueta, puede usar el método de
find , que devolverá un solo objeto BeautifulSoup . 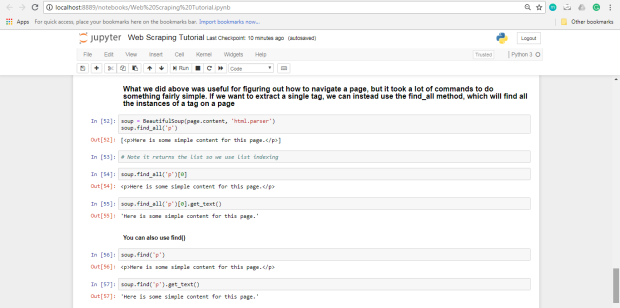
Si desea abrir este cuaderno, vaya al tutorial de raspado web.
Ahora, te mostraré cómo realizar el raspado web con Python 3 y la biblioteca BeautifulSoup . Recogeremos los pronósticos meteorológicos del Servicio Meteorológico Nacional y luego los analizaremos utilizando la biblioteca Pandas .

Ahora sabemos lo suficiente como para proceder a extraer información
sobre el clima local del sitio web del Servicio Nacional de
Meteorología. El primer paso es encontrar la página que queremos raspar. Extraeremos información meteorológica sobre el centro de San Francisco de esta página .
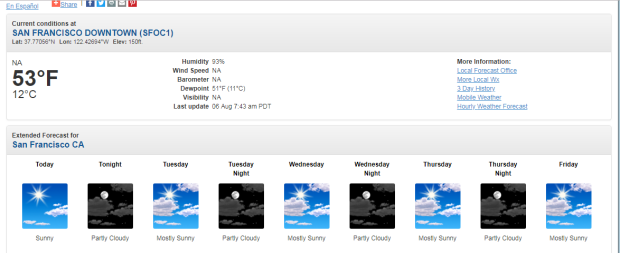
Una vez que abra esta página, use CRTL + MAYÚS + I para inspeccionar el elemento, pero aquí estamos interesados en esta columna en particular (San Francisco CA).
Entonces, al hacer clic derecho en la página cerca de donde dice
"Pronóstico extendido", luego hacer clic en "Inspeccionar", abriremos la
etiqueta que contiene el texto "Pronóstico extendido" en el panel de
elementos.

Luego podemos desplazarnos hacia arriba en el panel de elementos para
encontrar el elemento "más externo" que contiene todo el texto que
corresponde a los pronósticos extendidos. En este caso, es una etiqueta
div con la identificación de seven-day-forecast.
Explore el div, descubrirá que cada elemento de pronóstico (como "Esta
noche", "Jueves" y "Jueves por la noche") está contenido en un
div con el tombstone-container clase. 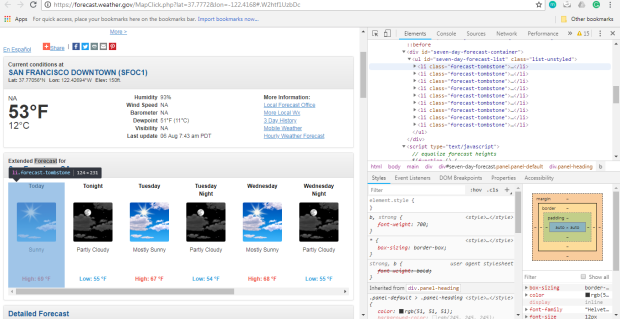
Ahora sabemos lo suficiente para descargar la página y comenzar a analizarla. En el siguiente código, nosotros:
- Descarga la página web que contiene el pronóstico.
- Crea una clase
BeautifulSouppara analizar la página. - Encuentra el
divcon id deseven-day-forecastyseven_dayaseven_day - Dentro de
seven_day, encuentra cada elemento de pronóstico individual. - Extraiga e imprima el primer artículo de pronóstico.
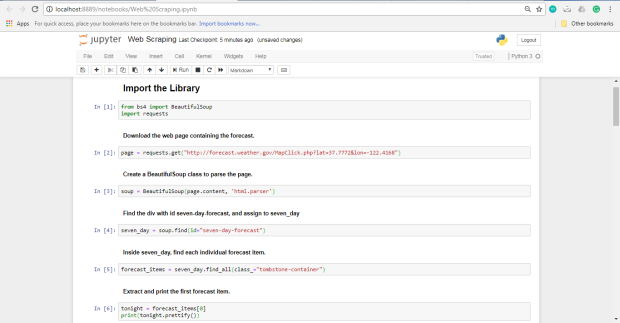
Extraer e imprimir el primer artículo de pronóstico

Como puede ver, dentro del artículo de pronóstico
tonight está toda la información que deseamos. Hay 4 piezas de información que podemos extraer: - El nombre del elemento de pronóstico - en este caso,
Today. - La descripción de las condiciones - esto se almacena en la propiedad del
titledeimg. - Una breve descripción de las condiciones - en este caso,
Sunny. - La temperatura baja - en este caso,
69 °F

Ahora que sabemos cómo extraer cada pieza individual de información,
podemos combinar nuestro conocimiento con los selectores de CSS y
enumerar las comprensiones para extraer todo de una vez.
En el siguiente código :
Seleccione todos los elementos con el
period-name clase dentro de un elemento con la clase tombstone-container en seven_day .
Use una lista de comprensión para llamar al método
get_text en cada objeto BeautifulSoup . 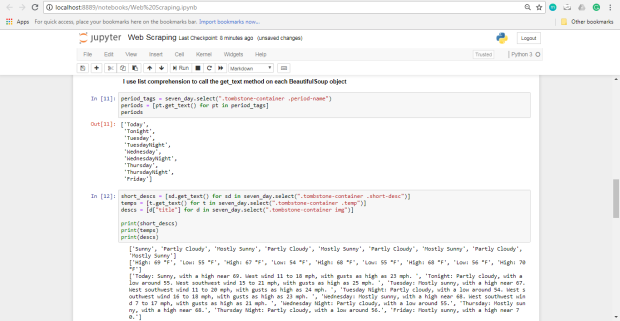
Combinando nuestros datos en Pandas DataFrame

Podemos usar una expresión regular y el método Series.str.extract para extraer los valores numéricos de temperatura.
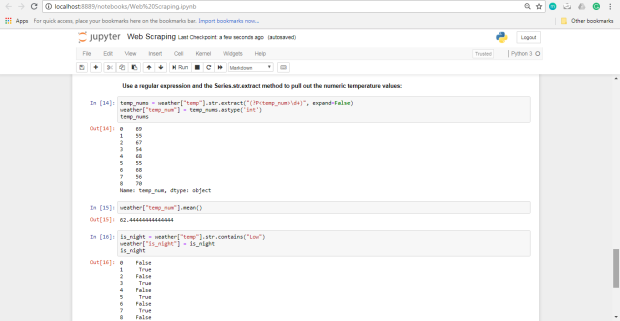

Si quieres abrir este cuaderno, ve a Web Scraping y GitHub
Espero que ahora tenga una buena comprensión de cómo raspar los datos de las páginas web. En las próximas semanas, haré raspado web
- Artículos de noticias
- Resultados deportivos
- Pronóstico del tiempo
- Precios de las acciones
- Precio minorista online etc.
Traducido de: Web Scraping with Python and BeautifulSoup – TheMenYouWantToBe&Co. – Medium


Comentarios
Publicar un comentario