Raspado web de las mentiras del presidente en 16 líneas de Python
Nota: este tutorial está disponible como una serie de videos y un cuaderno Jupyter , y el conjunto de datos de mentiras está disponible como un archivo CSV .
Al final de este tutorial, podrá raspar los datos de una página web estática utilizando las solicitudes y las bibliotecas de Beautiful Soup , y exportar esos datos a un archivo de texto estructurado utilizando la biblioteca de pandas .
Este es un escenario común: encuentra una página web que contiene datos que desea analizar, pero no se presenta en un formato que pueda descargar fácilmente y leer en su herramienta de análisis de datos favorita. Podría imaginar copiar y pegar manualmente los datos en una hoja de cálculo, pero en la mayoría de los casos, eso lleva demasiado tiempo. Una técnica llamada web scraping es una forma útil de automatizar este proceso.
¿Qué es web scraping? Es el proceso de extracción de información de una página web aprovechando los patrones en el código subyacente de la página web. ¡Vamos a empezar a buscar estos patrones!
 Al convertir esto en un conjunto de datos, puede pensar en cada mentira como un "registro" con cuatro campos:
Al convertir esto en un conjunto de datos, puede pensar en cada mentira como un "registro" con cuatro campos:
¿Por qué importa el formato? Debido a que es muy probable que el código subyacente a la página web "etiquete" esos campos de manera diferente, y podemos aprovechar ese patrón al raspar la página. Echemos un vistazo al código fuente, conocido como HTML:
Estas son las primeras líneas que verá si ve la fuente del artículo del New York Times:
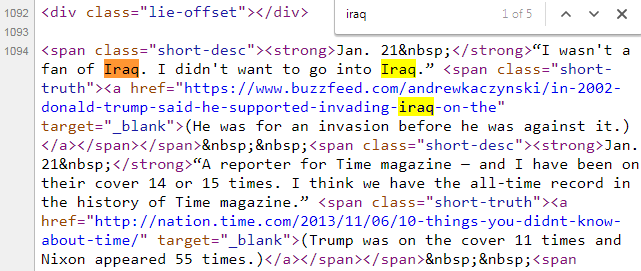
 Localicemos la primera mentira buscando el texto "iraq" en el HTML:
Localicemos la primera mentira buscando el texto "iraq" en el HTML:
 ¡Afortunadamente, solo tiene que entender tres datos básicos sobre HTML para comenzar con el raspado web!
¡Afortunadamente, solo tiene que entender tres datos básicos sobre HTML para comenzar con el raspado web!
Por ejemplo, una etiqueta es
Para el propósito de raspado web, no es necesario que entiendas el significado de
El texto de los estudiantes de la Escuela de Datos sería en negrita, porque todo ese texto está entre la etiqueta de apertura
Hola estudiantes de Data School
El punto central para quitar de este ejemplo es que las etiquetas "marcan" el texto desde donde se abren hasta donde se cierran, sin importar si están anidadas dentro de otras etiquetas.
¿Lo tengo? ¡Ya sabes lo suficiente sobre HTML para comenzar a raspar en la web!
(Tenga en cuenta que
Echemos otro vistazo al artículo y comparémoslo con el HTML:
 Es posible que hayas notado que cada registro tiene el siguiente formato:
Es posible que hayas notado que cada registro tiene el siguiente formato:
Hay una etiqueta externa
Vamos a pedirle a Beautiful Soup que encuentre todos los discos:
También podemos dividir el objeto como una lista, para examinar los primeros tres resultados:

¡Se ve bien!
Ahora hemos recopilado los 116 registros, pero aún debemos separar cada registro en sus cuatro componentes (fecha, mentira, explicación y URL) para darle cierta estructura al conjunto de datos.
Aunque
Para ubicar la fecha, podemos usar su método
Este código busca
Como queremos extraer el texto entre las etiquetas de apertura y cierre , podemos acceder a su atributo de
Sin embargo, debe saber que una secuencia de escape representa un solo carácter dentro de una cadena. Vamos a cortarlo desde el final de la cadena:
Podemos cortar esta lista para extraer el segundo elemento:
La primera opción es dividir el atributo de
Examinemos la etiqueta
Beautiful Soup trata los atributos de etiqueta y sus valores como pares clave-valor en un diccionario: usted pone el nombre del atributo entre corchetes (como una clave del diccionario), y recupera el valor del atributo:
Puede aplicar estos dos métodos al objeto de
Y, por supuesto, hay muchos más métodos y atributos disponibles para usted, que se describen en la documentación de Beautiful Soup .
La estructura de datos principal en pandas es el "Marco de datos", que es adecuado para datos tabulares con columnas de diferentes tipos, similar a una hoja de cálculo de Excel o una tabla SQL. Podemos convertir nuestra lista de tuplas en un DataFrame pasándola al constructor de DataFrame y especificando los nombres de columna deseados:
 Los números en el lado izquierdo del DataFrame se conocen como el "índice", que actúa como identificadores de las filas. Como no especificamos un índice, se asignó automáticamente como los números enteros de 0 a 115.
Los números en el lado izquierdo del DataFrame se conocen como el "índice", que actúa como identificadores de las filas. Como no especificamos un índice, se asignó automáticamente como los números enteros de 0 a 115.
Podemos examinar la parte inferior del DataFrame usando el método
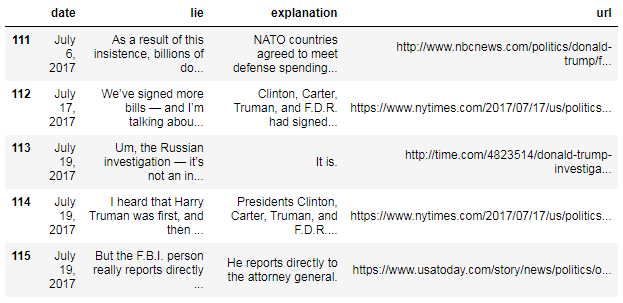 ¿Notó que "enero" se abrevia, mientras que "julio" no lo es?
Es mejor dar formato a sus datos de manera consistente, por lo que
vamos a convertir la columna de fecha al formato especial "fecha y hora"
de pandas:
¿Notó que "enero" se abrevia, mientras que "julio" no lo es?
Es mejor dar formato a sus datos de manera consistente, por lo que
vamos a convertir la columna de fecha al formato especial "fecha y hora"
de pandas:
Echemos un vistazo a los resultados:
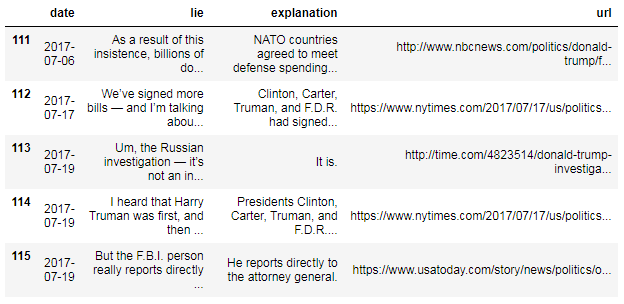 La columna de fecha no solo tiene un formato consistente, sino que los pandas también proporcionan una gran cantidad de funciones relacionadas con la fecha porque están en un formato de fecha y hora.
La columna de fecha no solo tiene un formato consistente, sino que los pandas también proporcionan una gran cantidad de funciones relacionadas con la fecha porque están en un formato de fecha y hora.
En el futuro, puede reconstruir este DataFrame leyendo el archivo CSV en pandas:
Por ejemplo, puede buscar una etiqueta accediendo a ella como un atributo:
Resumen
Este es un tutorial introductorio sobre raspado web en Python. Todo lo que se requiere para seguir es una comprensión básica del lenguaje de programación Python.Al final de este tutorial, podrá raspar los datos de una página web estática utilizando las solicitudes y las bibliotecas de Beautiful Soup , y exportar esos datos a un archivo de texto estructurado utilizando la biblioteca de pandas .
contorno
- ¿Qué es web scraping?
- Examinando el artículo del New York Times.
- Leyendo la página web en Python
- Analizando el HTML usando Beautiful Soup
- Construyendo el conjunto de datos
- Resumen: 16 líneas de código Python
¿Qué es web scraping?
El 21 de julio de 2017, el New York Times actualizó un artículo de opinión titulado Trump's Lies , que detalla cada mentira pública que el presidente ha dicho desde que asumió el cargo. Debido a que este es un periódico, la información fue (por supuesto) publicada como un bloque de texto. Este es un gran formato para el consumo humano, pero no puede ser comprendido fácilmente por una computadora. En este tutorial, extraeremos las mentiras del presidente del artículo del New York Times y las almacenaremos en un conjunto de datos estructurado.Este es un escenario común: encuentra una página web que contiene datos que desea analizar, pero no se presenta en un formato que pueda descargar fácilmente y leer en su herramienta de análisis de datos favorita. Podría imaginar copiar y pegar manualmente los datos en una hoja de cálculo, pero en la mayoría de los casos, eso lleva demasiado tiempo. Una técnica llamada web scraping es una forma útil de automatizar este proceso.
¿Qué es web scraping? Es el proceso de extracción de información de una página web aprovechando los patrones en el código subyacente de la página web. ¡Vamos a empezar a buscar estos patrones!
Examinando el artículo del New York Times.
Aquí está la forma en que el artículo presentó la información:- La fecha de la mentira.
- La mentira en sí (como una cita).
- La breve explicación del escritor de por qué era una mentira.
- La URL de un artículo que justifica la afirmación de que era una mentira.
¿Por qué importa el formato? Debido a que es muy probable que el código subyacente a la página web "etiquete" esos campos de manera diferente, y podemos aprovechar ese patrón al raspar la página. Echemos un vistazo al código fuente, conocido como HTML:
Examinando el HTML
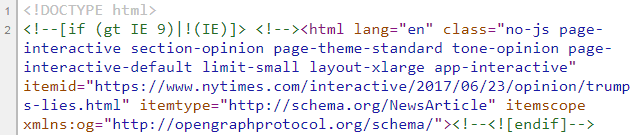
Para ver el código HTML que genera una página web, haga clic con el botón derecho sobre él y seleccione "Ver origen de página" en Chrome o Firefox, "Ver código de fuente" en Internet Explorer o "Mostrar origen de página" en Safari. (Si esa opción no aparece en Safari, simplemente abra las Preferencias de Safari, seleccione la pestaña Avanzado y marque "Mostrar menú de Desarrollo en la barra de menú").Estas son las primeras líneas que verá si ve la fuente del artículo del New York Times:
Hecho 1: HTML consiste en etiquetas
Puede ver que el HTML contiene el texto del artículo, junto con las "etiquetas" (especificadas con corchetes angulares) que "marcan" el texto. ("HTML" significa lenguaje de marcado de hipertexto).Por ejemplo, una etiqueta es
<strong> , que significa "usar formato en negrita". Hay una etiqueta <strong> antes del "21 de enero" y una etiqueta </strong> después de ella. La primera es una "etiqueta de apertura" y la segunda es una "etiqueta de cierre" (indicada por / ), que indica al navegador web dónde comenzar y detener la aplicación del formato. En otras palabras, esta etiqueta le dice al navegador web que haga que el texto "21 de enero" esté en negrita. (No te preocupes por la trataremos con eso más adelante). Hecho 2: las etiquetas pueden tener atributos
Las etiquetas HTML pueden tener "atributos", que se especifican en la etiqueta de apertura. Por ejemplo,<span class="short-desc"> indica que esta etiqueta en particular <span> tiene un atributo de class con un valor de short-desc . Para el propósito de raspado web, no es necesario que entiendas el significado de
<span> , class o short-desc . short-desc .
En su lugar, solo necesita reconocer que las etiquetas pueden tener
atributos y que se especifican de esta manera en particular. Hecho 3: las etiquetas se pueden anidar
Vamos a pretender que mi código HTML dice:Hello <strong><em>Data School</em> students</strong> El texto de los estudiantes de la Escuela de Datos sería en negrita, porque todo ese texto está entre la etiqueta de apertura
<strong> y la etiqueta de cierre </strong> . El texto Data School también estaría en cursiva, porque la etiqueta <em> significa "usar cursiva". El texto "Hola" no estaría en negrita ni en cursiva, porque no está dentro de las etiquetas <strong> o <em> . Por lo tanto, aparecería como sigue: Hola estudiantes de Data School
El punto central para quitar de este ejemplo es que las etiquetas "marcan" el texto desde donde se abren hasta donde se cierran, sin importar si están anidadas dentro de otras etiquetas.
¿Lo tengo? ¡Ya sabes lo suficiente sobre HTML para comenzar a raspar en la web!
Leyendo la página web en Python
Lo primero que debemos hacer es leer el HTML de este artículo en Python, lo que haremos usando la biblioteca de solicitudes . (Si no lo tiene, puedepip install requests desde la línea de comandos). import requests r = requests.get('https://www.nytimes.com/interactive/2017/06/23/opinion/trumps-lies.html')El código anterior recupera nuestra página web de la URL y almacena el resultado en un objeto de "respuesta" llamado
r . El objeto de respuesta tiene un atributo de text , que contiene el mismo código HTML que vimos al ver la fuente desde nuestro navegador web:# print the first 500 characters of the HTML print(r.text[0:500])
<!DOCTYPE html> <!--[if (gt IE 9)|!(IE)]> <!--><html lang="en" class="no-js page-interactive section-opinion page-theme-standard tone-opinion page-interactive-default limit-small layout-xlarge app-interactive" itemid="https://www.nytimes.com/interactive/2017/06/23/opinion/trumps-lies.html" itemtype="http://schema.org/NewsArticle" itemscope xmlns:og="http://opengraphprotocol.org/schema/"><!--<![endif]--> <!--[if IE 9]> <html lang="en" class="no-js ie9 lt-ie10 page-interactive section-opinion page
Analizando el HTML usando Beautiful Soup
Vamos a analizar el HTML utilizando la biblioteca Beautiful Soup 4 , que es una popular biblioteca de Python para el rastreo web. (Si no lo tiene, puedepip install beautifulsoup4 desde la línea de comandos).from bs4 import BeautifulSoup soup = BeautifulSoup(r.text, 'html.parser')El código anterior analiza el HTML (almacenado en
r.text ) en un objeto especial llamado soup que la biblioteca Beautiful Soup entiende. En otras palabras, Beautiful Soup está leyendo el HTML y dando sentido a su estructura. (Tenga en cuenta que
html.parser es el analizador incluido con la biblioteca estándar de Python, aunque Beautiful Soup puede usar otros analizadores. Vea las diferencias entre analizadores para obtener más información). Recopilación de todos los registros.
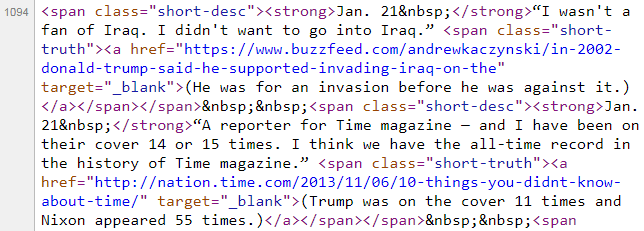
El código de Python anterior es el código estándar que uso con cada proyecto de raspado web. ¡Ahora, vamos a comenzar a aprovechar los patrones que notamos en el formato del artículo para construir nuestro conjunto de datos!Echemos otro vistazo al artículo y comparémoslo con el HTML:
<span
class="short-desc"><strong> DATE </strong> LIE <span
class="short-truth"><a href="URL"> EXPLANATION
</a></span></span> Hay una etiqueta externa
<span> , y luego anidada dentro de ella es una etiqueta <strong> más otra etiqueta <span> , que a su vez contiene una etiqueta <a> . Todas estas etiquetas afectan el formato del texto. Y como el New York Times desea que cada registro aparezca de manera consistente en su navegador web, sabemos que cada registro se etiquetará de manera consistente en el HTML. ¡Este es el patrón que nos permite construir nuestro conjunto de datos! Vamos a pedirle a Beautiful Soup que encuentre todos los discos:
results = soup.find_all('span', attrs={'class':'short-desc'})Este código busca en el objeto de
soup todas las etiquetas <span> con el atributo class="short-desc" . Devuelve un objeto especial de Beautiful Soup (llamado "ResultSet") que contiene los resultados de la búsqueda. results actúan como una lista de Python , por lo que podemos verificar su longitud:len(results)
116
Hay 116 resultados, lo que parece razonable dada la longitud del artículo.
(Si este número no pareciera razonable, examinaríamos más el HTML para
determinar si nuestras suposiciones sobre los patrones en el HTML eran
incorrectas). También podemos dividir el objeto como una lista, para examinar los primeros tres resultados:
results[0:3]
[<span class="short-desc"><strong>Jan. 21 </strong>“I wasn't a fan of Iraq. I didn't want to go into Iraq.” <span class="short-truth"><a href="https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the" target="_blank">(He was for an invasion before he was against it.)</a></span></span>,
<span class="short-desc"><strong>Jan. 21 </strong>“A reporter for Time magazine — and I have been on their cover 14 or 15 times. I think we have the all-time record in the history of Time magazine.” <span class="short-truth"><a href="http://nation.time.com/2013/11/06/10-things-you-didnt-know-about-time/" target="_blank">(Trump was on the cover 11 times and Nixon appeared 55 times.)</a></span></span>,
<span class="short-desc"><strong>Jan. 23 </strong>“Between 3 million and 5 million illegal votes caused me to lose the popular vote.” <span class="short-truth"><a href="https://www.nytimes.com/2017/01/23/us/politics/donald-trump-congress-democrats.html" target="_blank">(There's no evidence of illegal voting.)</a></span></span>]
También verificaremos que el último resultado en este objeto coincida con el último registro del artículo: results[-1]
¡Se ve bien!
Ahora hemos recopilado los 116 registros, pero aún debemos separar cada registro en sus cuatro componentes (fecha, mentira, explicación y URL) para darle cierta estructura al conjunto de datos.
Extrayendo la fecha
El raspado web es a menudo un proceso iterativo, en el que experimenta con su código hasta que funciona exactamente como lo desea. Para simplificar la experimentación, comenzaremos trabajando solo con el primer registro en el objeto deresults , y luego, modificaremos nuestro código para usar un bucle:first_result = results[0] first_result
Aunque
first_result puede parecer una cadena de Python, notará que no hay comillas a su alrededor. En cambio, es otro objeto especial de Beautiful Soup (llamado "Etiqueta") que tiene métodos y atributos específicos Para ubicar la fecha, podemos usar su método
find() para encontrar una sola etiqueta que coincida con un patrón específico, en contraste con el método find_all() que usamos anteriormente para encontrar todas las etiquetas que coincidan con un patrón:first_result.find('strong')
Este código busca
first_result para la primera instancia de una etiqueta <strong> , y nuevamente devuelve un objeto "Tag" de Beautiful Soup (no una cadena). Como queremos extraer el texto entre las etiquetas de apertura y cierre , podemos acceder a su atributo de
text , que de hecho devuelve una cadena de Python normal:first_result.find('strong').text
'Jan. 21\xa0'
¿Qué es \xa0 ? Realmente no necesita saber esto, pero se denomina "secuencia de escape" que representa el personaje que vimos anteriormente en la fuente HTML. Sin embargo, debe saber que una secuencia de escape representa un solo carácter dentro de una cadena. Vamos a cortarlo desde el final de la cadena:
first_result.find('strong').text[0:-1]
'Jan. 21'
Finalmente, agregaremos el año, ya que no queremos que nuestro conjunto de datos incluya fechas ambiguas:first_result.find('strong').text[0:-1] + ', 2017'
'Jan. 21, 2017'
Extrayendo la mentira
Echemos otro vistazo afirst_result : first_result
<span class="short-desc"><strong>Jan. 21 </strong>“I wasn't a fan of Iraq. I didn't want to go into Iraq.” <span class="short-truth"><a href="https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the" target="_blank">(He was for an invasion before he was against it.)</a></span></span>
Nuestro objetivo es extraer las dos frases sobre Irak. Desafortunadamente, no hay un par de etiquetas de apertura y cierre que comiencen inmediatamente antes de la mentira y terminen inmediatamente después de la mentira . Por lo tanto, vamos a tener que utilizar una técnica diferente: first_result.contents
[<strong>Jan. 21 </strong>, "“I wasn't a fan of Iraq. I didn't want to go into Iraq.” ", <span class="short-truth"><a href="https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the" target="_blank">(He was for an invasion before he was against it.)</a></span>]
La "etiqueta" first_result tiene un atributo de contents , que devuelve una lista de Python que contiene sus "hijos". Que son los niños Son las etiquetas y cadenas que están anidadas dentro de una etiqueta. Podemos cortar esta lista para extraer el segundo elemento:
first_result.contents[1]
"“I wasn't a fan of Iraq. I didn't want to go into Iraq.” "
Finalmente, recortaremos las comillas y el espacio extra al final: first_result.contents[1][1:-2]
"I wasn't a fan of Iraq. I didn't want to go into Iraq."
Extrayendo la explicacion
Basándose en lo que ya ha visto, es posible que haya descubierto que tenemos al menos dos opciones para extraer el tercer componente del registro, que es la explicación del autor de por qué la declaración del Presidente fue una mentira.La primera opción es dividir el atributo de
contents , como hicimos al extraer la mentira: first_result.contents[2]
<span class="short-truth"><a href="https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the" target="_blank">(He was for an invasion before he was against it.)</a></span>
La segunda opción es buscar la etiqueta circundante, como hicimos al extraer la fecha: first_result.find('a')
<a href="https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the" target="_blank">(He was for an invasion before he was against it.)</a>
De cualquier manera, podemos acceder al atributo de text y luego cortar los paréntesis de apertura y cierre: first_result.find('a').text[1:-1]
'He was for an invasion before he was against it.'
Extraer la URL
Finalmente, queremos extraer la URL del artículo que justifica la afirmación del escritor de que el Presidente estaba mintiendo.Examinemos la etiqueta
<a> dentro de first_result : first_result.find('a')
<a href="https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the" target="_blank">(He was for an invasion before he was against it.)</a>
Hasta ahora, en este tutorial, hemos estado extrayendo texto que está entre etiquetas . En este caso, el texto que queremos extraer se encuentra dentro de la etiqueta en sí . Específicamente, queremos acceder al valor del atributo href dentro de la etiqueta <a> . Beautiful Soup trata los atributos de etiqueta y sus valores como pares clave-valor en un diccionario: usted pone el nombre del atributo entre corchetes (como una clave del diccionario), y recupera el valor del atributo:
first_result.find('a')['href']
'https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the'
Resumen: Métodos y atributos de la hermosa sopa
Antes de que terminemos de construir el conjunto de datos, quiero resumir algunas formas en que puedes interactuar con los objetos de Beautiful Soup.Puede aplicar estos dos métodos al objeto de
soup inicial o al objeto de etiqueta (como first_result ): -
find(): busca la primera etiqueta coincidente y devuelve un objeto Tag -
find_all(): busca todas las etiquetas coincidentes y devuelve un objeto ResultSet (que puede tratar como una lista de etiquetas)
first_result ) usando estos dos atributos: -
text: extrae el texto de una etiqueta y devuelve una cadena -
contents: extrae los hijos de una etiqueta y devuelve una lista de etiquetas y cadenas
Y, por supuesto, hay muchos más métodos y atributos disponibles para usted, que se describen en la documentación de Beautiful Soup .
Construyendo el conjunto de datos
Ahora que hemos descubierto cómo extraer los cuatro componentes defirst_result , podemos crear un bucle para repetir este proceso en los 116 results . Almacenaremos la salida en una lista de tuplas llamadas records : records = []
for result in results:
date = result.find('strong').text[0:-1] + ', 2017'
lie = result.contents[1][1:-2]
explanation = result.find('a').text[1:-1]
url = result.find('a')['href']
records.append((date, lie, explanation, url))
Como hubo 116 results , deberíamos tener 116 records : len(records)
116
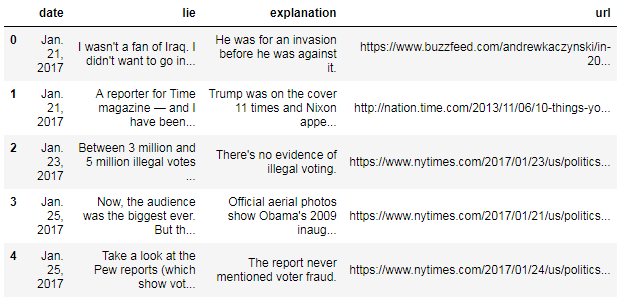
Vamos a hacer una revisión rápida de los primeros tres registros: records[0:3]
[('Jan. 21, 2017',
"I wasn't a fan of Iraq. I didn't want to go into Iraq.",
'He was for an invasion before he was against it.',
'https://www.buzzfeed.com/andrewkaczynski/in-2002-donald-trump-said-he-supported-invading-iraq-on-the'),
('Jan. 21, 2017',
'A reporter for Time magazine — and I have been on their cover 14 or 15 times. I think we have the all-time record in the history of Time magazine.',
'Trump was on the cover 11 times and Nixon appeared 55 times.',
'http://nation.time.com/2013/11/06/10-things-you-didnt-know-about-time/'),
('Jan. 23, 2017',
'Between 3 million and 5 million illegal votes caused me to lose the popular vote.',
"There's no evidence of illegal voting.",
'https://www.nytimes.com/2017/01/23/us/politics/donald-trump-congress-democrats.html')]
¡Se ve bien! Aplicando una estructura de datos tabular.
El último paso importante en este proceso es aplicar una estructura de datos tabular a nuestra estructura existente (que es una lista de tuplas). Vamos a hacer esto utilizando la biblioteca de pandas , una biblioteca de Python increíblemente popular para el análisis y la manipulación de datos. (Si no lo tiene, aquí están las instrucciones de instalación ).La estructura de datos principal en pandas es el "Marco de datos", que es adecuado para datos tabulares con columnas de diferentes tipos, similar a una hoja de cálculo de Excel o una tabla SQL. Podemos convertir nuestra lista de tuplas en un DataFrame pasándola al constructor de DataFrame y especificando los nombres de columna deseados:
import pandas as pd
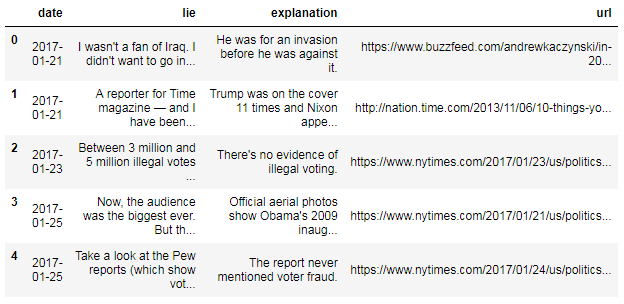
df = pd.DataFrame(records, columns=['date', 'lie', 'explanation', 'url'])head() , que le permite examinar la parte superior del DataFrame: df.head()
Podemos examinar la parte inferior del DataFrame usando el método
tail() : df.tail()
df['date'] = pd.to_datetime(df['date']) Echemos un vistazo a los resultados:
df.head()
df.tail()
Exportando el conjunto de datos a un archivo CSV
Finalmente, usaremos pandas para exportar el marco de datos a un archivo CSV (valores separados por comas), que es la forma más simple y común de almacenar datos tabulares en un archivo de texto:df.to_csv('trump_lies.csv', index=False, encoding='utf-8') index en False para decirle a los pandas que no lo necesitamos para incluir el índice (los enteros de 0 a 115) en el archivo CSV.
¡Debería poder encontrar este archivo en su directorio de trabajo y
abrirlo en cualquier editor de texto o programa de hoja de cálculo! En el futuro, puede reconstruir este DataFrame leyendo el archivo CSV en pandas:
df = pd.read_csv('trump_lies.csv', parse_dates=['date'], encoding='utf-8') Resumen: 16 líneas de código Python
Aquí están las 16 líneas de código que utilizamos para raspar la página web, extraer los datos relevantes, convertirlos en un conjunto de datos tabulares y exportarlos a un archivo CSV:import requests
r = requests.get('https://www.nytimes.com/interactive/2017/06/23/opinion/trumps-lies.html')
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
results = soup.find_all('span', attrs={'class':'short-desc'})
records = []
for result in results:
date = result.find('strong').text[0:-1] + ', 2017'
lie = result.contents[1][1:-2]
explanation = result.find('a').text[1:-1]
url = result.find('a')['href']
records.append((date, lie, explanation, url))
import pandas as pd
df = pd.DataFrame(records, columns=['date', 'lie', 'explanation', 'url'])
df['date'] = pd.to_datetime(df['date'])
df.to_csv('trump_lies.csv', index=False, encoding='utf-8')
Apéndice A: consejos de raspado web
- El raspado web funciona mejor con páginas web estáticas y bien estructuradas . El contenido dinámico o interactivo en una página web a menudo no es accesible a través de la fuente HTML, ¡lo que dificulta mucho el raspado!
- El raspado web es un enfoque "frágil" para crear un conjunto de datos. El HTML en una página que está raspando puede cambiar en cualquier momento , lo que puede hacer que su raspador deje de funcionar.
- Si puede descargar los datos que necesita de un sitio web, o si el sitio web proporciona una API con acceso a datos , esos enfoques son preferibles al raspado, ya que son más fáciles de implementar y es menos probable que se rompan.
- Si está raspando muchas páginas del mismo sitio web (en rápida sucesión), es mejor insertar retrasos en su código para no abrumar las solicitudes del sitio web. Si el sitio web decide que está causando un problema, pueden bloquear su dirección IP (¡lo que puede afectar a todos en su edificio!)
- Antes de raspar un sitio web, debe revisar su archivo robots.txt (también conocido como el estándar de exclusión de Robots ) para verificar si está "autorizado" a raspar su sitio web. (Aquí está el archivo robots.txt para nytimes.com ).
Apéndice B: recursos de raspado web
- La documentación de Beautiful Soup está escrita como un tutorial y vale la pena leerla para obtener una comprensión detallada de la biblioteca.
- Para ver más ejemplos de Beautiful Soup, vea Web Scraping 101 with Python , More web scraping with Python , y esta lección de web scraping del curso "Text As Data" de Stanford.
- Web Scraping with Python es un video tutorial de 3 horas que cubre Beautiful Soup y otras herramientas de raspado. (Las diapositivas y el código también están disponibles.)
- Scrapy es un marco de aplicación popular que es útil para proyectos de raspado web más complejos.
- Cómo un genio matemático pirateaba OkCupid para encontrar el amor verdadero y cómo el Hollywood de ingeniería inversa de Netflix son dos ejemplos divertidos del uso del raspado web para crear un conjunto de datos interesante.
Apéndice C: Sintaxis alternativa para Beautiful Soup
Vale la pena señalar que Beautiful Soup en realidad ofrece múltiples formas de expresar el mismo comando. Tiendo a usar la opción más detallada, ya que creo que hace que el código sea legible, pero es útil poder reconocer la sintaxis alternativa, ya que es posible que lo veas en otro lugar.Por ejemplo, puede buscar una etiqueta accediendo a ella como un atributo:
# search for a tag by name
first_result.find('strong')
# shorter alternative: access it like an attribute
first_result.strong
<strong>Jan. 21 </strong>
También puede buscar varias etiquetas de varias maneras diferentes:# search for multiple tags by name and attribute
results = soup.find_all('span', attrs={'class':'short-desc'})
# shorter alternative: if you don't specify a method, it's assumed to be find_all()
results = soup('span', attrs={'class':'short-desc'})
# even shorter alternative: you can specify the attribute as if it's a parameter
results = soup('span', class_='short-desc')
Para más detalles, revisa la documentación de Beautiful Soup . 

Comentarios
Publicar un comentario